卷积神经网络和深度学习
背景
浅层学习:传统模式识别的经典模型,需要人工提取特征,然后使用分类器进行分类。这种方法的缺点是特征提取需要大量的人力和时间,而且特征的选择往往是主观的,不一定是最优的。
深度学习:是一种自动提取特征的、端到端的机器学习方法。深度学习的核心是神经网络,每一层神经元都可以自动提取特征,然后传递给下一层神经元。随着特征的传递,其表示的层次逐级升高,最终得到高层次的抽象特征,这些特征可以用于分类、回归等任务。
下面要介绍的卷积神经网络(Convolutional Neural Network,
卷积 Convolution
卷积是一种数学运算,它在信号处理、图像处理等领域有着广泛的应用。在卷积神经网络中,卷积是一种特殊的线性运算,它可以有效地提取图像的特征。本文介绍的卷积为离散卷积。
为什么要使用卷积
考虑一个
如果我们采取部分连接的方式,即每
如果我们使用共享参数学习的方式,假设我们有
但是这样的话,我们的模型可能严重欠拟合,因为参数量太少了。这时我们可以采取多个“过滤器”的方式,将“过滤器“的数量设为
对于一个彩色图像,它一般是一个形如 Red、Green、Blue 三个通道)。而卷积核是一个
卷积处理的结果也是一个矩阵,记为
其中
如何理解卷积运算?
我们可以想象把卷积核嵌入原始矩阵的某个位置上(对其网格哦),然后卷积核上的元素就会与原始矩阵上的元素“重叠”,将重叠的元素相乘,并将它们求和,就得到了卷积核在这个位置(即卷积核中心)上的输出值。把卷积核在整个矩阵上移动,遍历所有可能的位置,保持输出值的相对位置不变,我们就得到了输出矩阵。
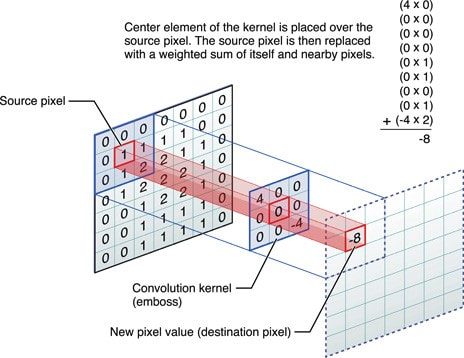
卷积的直观展示
池化 Pooling
池化是一种非线性下采样的操作,它可以减少数据量,同时保留重要的特征。池化操作通常在卷积层之后,可以减少特征的数量,从而减少计算量,并最大程度上保留特征。
池化操作的过程是这样的:对于一个
常见的池化操作有最大池化和平均池化。顾名思义,最大池化是取池化窗口中的最大值,平均池化是取池化窗口中的平均值。
卷积神经网络
卷积神经网络的主要结构包括卷积层、池化层、全连接层和
之后,串联起整个卷积神经网络,我们发现它实质上是一个输入为高维数据(如图像)、输出为类别的模型。因此,我们依然可以使用上一节介绍的有监督的学习机制和反向传播算法来训练卷积神经网络。
为何可以使用 BP 算法
卷积神经网络虽然结构复杂,但是它实质上仍然是一个复合函数。我们可以将卷积神经网络,从中间的任意一层、到最终的损失函数输出,看成一个复合函数。此时,我们将输入看作是参数,而该层的参数看作是自变量,将损失函数看作是因变量,我们可以计算出损失函数对参数的梯度(由于链式法则,计算时很可能用到下一层的梯度,所以使用反向传播),然后使用梯度下降等方法来更新参数。
优化
Dropout
Dropout 是一种正则化的方法,它可以减少过拟合。Dropout 的原理是在训练过程中,随机地让一部分神经元失活,这样可以减少神经元之间的依赖性,从而减少过拟合。
Batch Normalization
Batch Normalization 也是一种正则化的方法,它的思想是在每一个小批量的数据上,对每一层的输入进行归一化,使得每一层的输入的均值为
Batch Normalization 的流程
对于一个小批量数据
其中
其中
下面是一个使用
深度学习的技巧
自己搭建一个简单的深度学习模型
“纸上得来终觉浅”。我们不妨自己动手搭建一个简单的深度学习模型。这样可以更好地理解深度学习的原理,也可以更好地掌握深度学习的技巧。
一个好的上手教程是:Deep Learning with PyTorch: A 60 Minute Blitz。这个教程搭建了一个简单的图像分类模型,并在 CIFAR-10 数据集上进行训练,是一个很好的入门教程。
- 数据增广:数据增广是一种数据扩充的方法,它可以通过对原始数据进行旋转、翻转、裁切、加噪音等操作,生成更多的数据,从而增加训练集的大小,减少过拟合。
- 预处理:
PCA白化、Zero Center(减去均值) 和Normalize(放缩到 1 内) 等。 - 初始化:增加随机性,
Calibration(使得输出的方差和输入的方差相等)等。 - 过滤器:卷积核的大小、步长、填充方式等。
- 池化大小
- 学习率:Step attenuation(学习率逐渐减小)、调优时选择小的学习率等。
- 在预训练模型上进行微调
对于不同的数据集,使用不同策略!
我们经常会遇到不同的数据集,而不同的数据集可能需要相应的策略才能达到好的训练效果。经验上,我们可以总结如下:
| 数据集较相似 | 数据集较不相似 | |
|---|---|---|
| 数据集较小 | 尝试第一层使用线性模型 | 较难处理,可以在不同层尝试线性模型 |
| 数据集较大 | 浅层神经网络 | 深层神经网络 |
- 激活函数和正则化:激活函数如
ReLU、Leaky ReLU、ELU等,正则化如L1、L2正则化、Dropout、Batch Normalization等。 - 图像分析与可视化:可以观察学习的准确率曲线、损失函数曲线等,以判断模型的训练效果。此外,我们还可以可视化中间层的参数等,以体现出模型的特征提取能力。
选择哪个 Epoch 的参数?
一般我们把在验证集上表现最好的参数作为最终的参数。如果我们的模型在验证集和训练集上表现差异很大,那么我们的模型很可能过拟合了。如果我们的模型在验证集和训练集上表现都不好,那么就应该发生了欠拟合。
深度学习工具箱
- PyTorch: tensors and dynamic neural networks in python (Python);
- TensorFlow: An end-to-end platform for machine learning;
- MatConvNet: A matlab toolbox implementing CNNs (Matlab);
- Caffe: C++, Python;
- Keras: A theano based deep learning library;
- Torch: provides a Matlab-like environment for ML algorithms in lua (Lua);
- Theano: CPU/GPU symbolic expression compiler in python (Python);
- MXNet: mix symbolic and imperative programming (Python, R, Julia...);
- CNTK: a unified deep-learning toolkit by Microsoft (C++, Python).
- PaddlePaddle: An Open-Source Deep Learning Platform (百度)
- MindSpore: 面向“端-边-云”全场景设计的AI框架(华为)
- MegEngine: 一个快速、可拓展、易于使用且支持自动求导的深度学习框架(旷视)
- Jittor:一个基于即时编译和元算子的高性能深度学习框架(清华大学)