自然语言处理
自然语言,即人类语言,是长期生物进化与社会演变下的产物。自然语言处理是以电子计算机为工具,对人类特有的书面形式和口头形式的自然语言的信息进行各种类型处理加工的技术。自然语言处理可以分为自然语言理解(机器读)和自然语言生成(机器写)两种。
自然语言处理的难点
- 语音歧义:主要体现在口语中,由于同音字、爆破音不完全、连读和重音不明等原因,导致语音识别的困难。例如:“我姓张”和“我姓章”在语音上是一样的,但是是不同的姓氏。
- 词义歧义:同一个词在不同的语境下有不同的含义。例如:“我喜欢苹果“,可能是指水果,也可能是指公司。
- 结构歧义:句子中词素的语法关系不明确。例如:“咬死了猎人的狗“,可能是陈述猎人的狗被咬死了,也可能是指那个咬死了猎人的狗。
自然语言不是一种形式化的语言,它的语法规则是不确定的。随着网络的发展,自然语言的表达方式也变得越来越多样化,同样也给自然语言处理带来了很大的挑战。
基于规则的方法
基于规则的方法的核心思想是通过词汇、形式文法等人为制定的规则来引入语言学知识,从而完成相应的自然语言处理任务。这一方法的好处是可以方便语言学家等不了解计算机编程的人员参与到自然语言处理的工作中,但是这种方法的缺点也很明显,即规则的制定是一个非常困难的过程,而且规则的数量也是非常庞大的,这就导致了这种方法的可扩展性和泛化能力不强。
基于机器学习的方法
基于机器学习的方法的核心思想是将自然语言处理任务转换为某种分类任务,在此基础上根据任务特性构建特征表示,并构建大规模的有标注预料,完成模型的训练。
这一方法的流程主要有:数据构建、数据预处理、特征构建和模型学习。整个方法的优势就在于可以自动学习,泛化能力也比较强。
基于大模型的方法
这一方法的主要流程为:大规模语言模型构建、预训练和微调。目前,基于大模型的方法在自然语言处理领域取得了很大的成功,融入了人们的生活。
文本规范化
在对自然语言进行处理之前,可能需要对其进行规范化处理。一般来说,规范化处理的范畴包括句子分割、词语切分、词语规范化等。
词语规范化
词语规范化是对词语进行统一化处理,使得不同的表达方式能够被统一为同一种表达方式。词语规范化的几个例子如下:
- 大小写转换:将所有的字母转换为大写或小写,主要作用于印欧语系和某些语言的特殊情况,如日文的片假名和平假名。
- 语义统一:将同义词统一为同一种表达方式,如
the US和USA。 - 拼写检查:对拼写错误的词语进行修正,如
teh和the。
分词(词语切分)
分词是自然语言处理中的一个重要步骤,其目的是将连续的字序列切分成具有语义的词序列。分词的目的是为了方便计算机对文本进行处理,例如文本的索引、检索、统计等。
以英语为代表的印欧语系中,词语和词语之间通常有分隔符来进行分割;但以汉语为代表的汉藏语系和以阿拉伯语为代表的闪-含语系,就不包括显式的分隔符。
基于最大匹配的中文分词
最大匹配法是一种简单而有效的中文分词方法。其基本思想即贪心搜索匹配给定的词典。
常用的分词库
- jieba:结巴分词是一个中文分词工具包,具有高效、简单易用、功能全面等特点。
- THULAC:清华大学自然语言处理与社会人文计算实验室开发的一套中文词法分析工具包,具有高效、准确、稳定等特点。
独热编码
独热编码是一种常用的文本规范化方法,其基本思想是将文本转换为向量。在独热编码中,每个词表示为一个长向量,这个向量的维度就是词表大小,向量中的每个元素都是
假设语料库中有三句话:
- 我|爱|中国
- 爸爸|妈妈|爱|我
- 爸爸|妈妈|爱|中国
经过分词后,我们构造词表为:{我,爱,中国,爸爸,妈妈},则独热编码后的结果为:
- 我|爱|中国:
- 爸爸|妈妈|爱|我:
- 爸爸|妈妈|爱|中国:
TF-IDF 编码
TF-IDF 编码即词频-逆文档频率篇章表示。词汇频率主要用来衡量词汇在特定文档中的重要程度,而逆向文档频率主要用来衡量词汇在整个语料库中的重要程度。
对于文档
其中
对于语料库
其中
综合上述两个公式,我们可以得到 TF-IDF 的计算公式:
TF-IDF 编码的优点是可以减少常用词汇的权重,增加不常用词汇的权重,从而更好地表示文档的特征。
分布式表示和 Word Embedding
独热编码和 TF-IDF 的缺点比较明显,它们只关注词的统计信息,而忽略了词之间的语义信息。并且特征较为稀疏,维度很大,造成了维度灾难。
Word Embedding 是一种词向量化的方法,其基本思想是通过训练大量语料,将词语映射到一个固定维度的低维空间中,使得词汇之间的语义相似度可以通过词语对应的向量之间的距离来衡量。一般而言,长度大概在百级别,并且向量的各个维度一般均非零。
对于分布式词向量的计算,一般通过神经网络来进行训练。在训练过程中,对应词的上下文词汇会被用来更新词向量,从而使得词向量能够更好地表示词汇的语义信息。经过训练后,词向量就能很好刻画出词汇之间的语义关系。譬如,我们可以通过词向量的相似度来计算词汇之间的相似度;我们也可以通过词向量的加减法来计算词汇之间的关系。
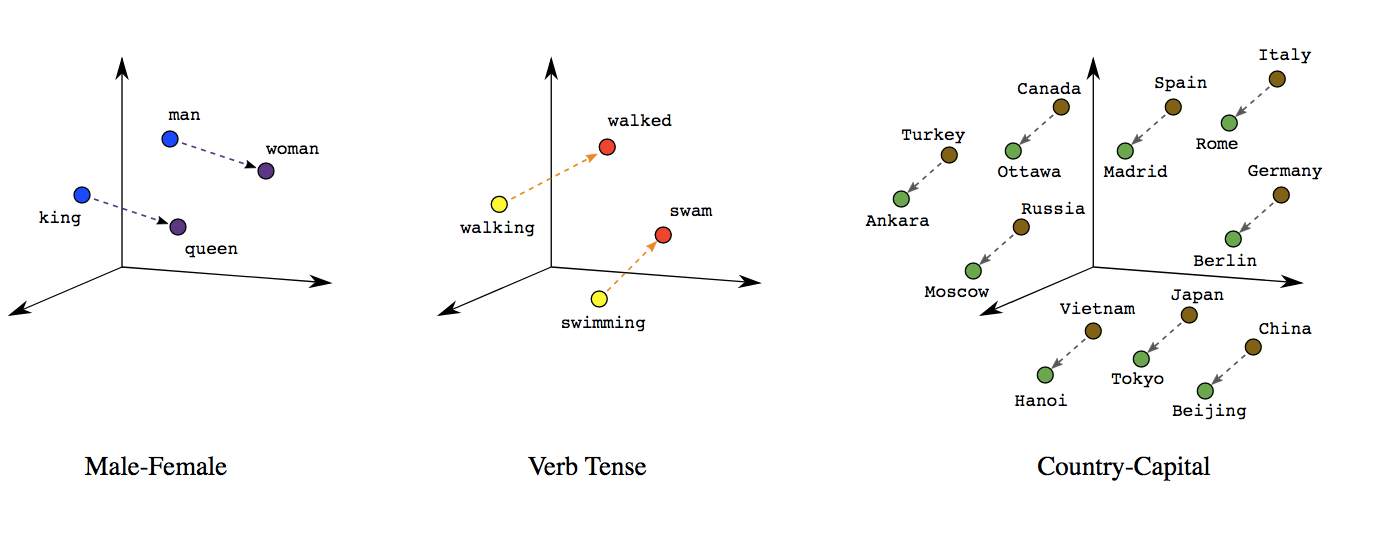
词向量加减法揭示的语义关系
word2vec
word2vec 是 Google 在 2013 年提出的一种词向量化的方法,其主要思想是通过浅层神经网络来训练词向量。
主要的思想是,给定一个大规模的文本语料库和固定的词表,对于语料库中的每一个文本,遍历每一个位置
神经网络计算的具体模式一般有两种:CBOW 和 Skip-gram。
Skip-gram 的网络结构包括三层:输入层、隐藏层和输出层。具体工作如下:
- 输入层:接受长度为
的独热编码向量 ,其中 表示词表的大小。这个向量对应了中心词 。 - 隐藏层:包含了一个
的参数矩阵 ,其中 表示词向量的维度。 即为词向量矩阵,其每一行对应一个词的词向量。显然, 就是中心词 的词向量,记作 。 - 输出层:包含了一个
的参数矩阵 ,其每一列对应一个词的词向量。输出层的计算公式为 ,得到向量 ,内部的数值代表了对每个候选词的打分。取出非中心词 的打分再进行归一化,得到了每个非中心词 的预测概率。
Skip-gram 的训练目标是最大化给定中心词
其中,中心词为
CBOW 的网络结构与 Skip-gram 相似,只是输入层和输出层的位置互换了。CBOW 的训练目标是最大化给定上下文词
预训练和 Encoder-Decoder 结构
语义是和上下文紧密结合的,语义也是变化的。现有的分布式词向量尽管已经能够很好地表示词汇之间的语义关系,但是它们仍然不能很好地适应动态的语义。这时,研究者们提出了通过预训练来嵌入更多的背景知识,提升模型的表征能力,同时使用 Encoder 结构来实现动态词向量表示。这一方法的来源在于:人类学习新任务时,大部分基于共有的背景知识,如常识和语言,这些背景知识是比较通用的;而在学习新任务时,人类会根据任务的特点来调整自己的处理方法。因此,预训练和 Encoder-Decoder 结构的结合,可以很好地提升模型的表征能力。
预训练需要收集大量的数据。由于有标记的数据较为昂贵和稀有,所以采取无标签的无监督学习方法进行训练。目前,预训练的模型基本基于 Transformer 结构,如 BERT、GPT 等。
BERT
BERT 是 Google 在 2018 年提出的一种预训练模型,其全称为Bidirectional Encoder Representations from Transformers。BERT 的主要思想是通过双向 Transformer 来学习文本的表征,从而提升模型的泛化能力。
BERT 的训练过程主要分为两个阶段:预训练和微调。
在预训练阶段,BERT 通过掩码语言模型和下一句预测两个任务来学习文本的表征。掩码语言模型的任务是给定一个句子,随机掩码掉其中的一些词,然后预测被掩码的词 [MASK]。通过这种方法,模型能够学习到更加准确的词语含义和上下文关联性。
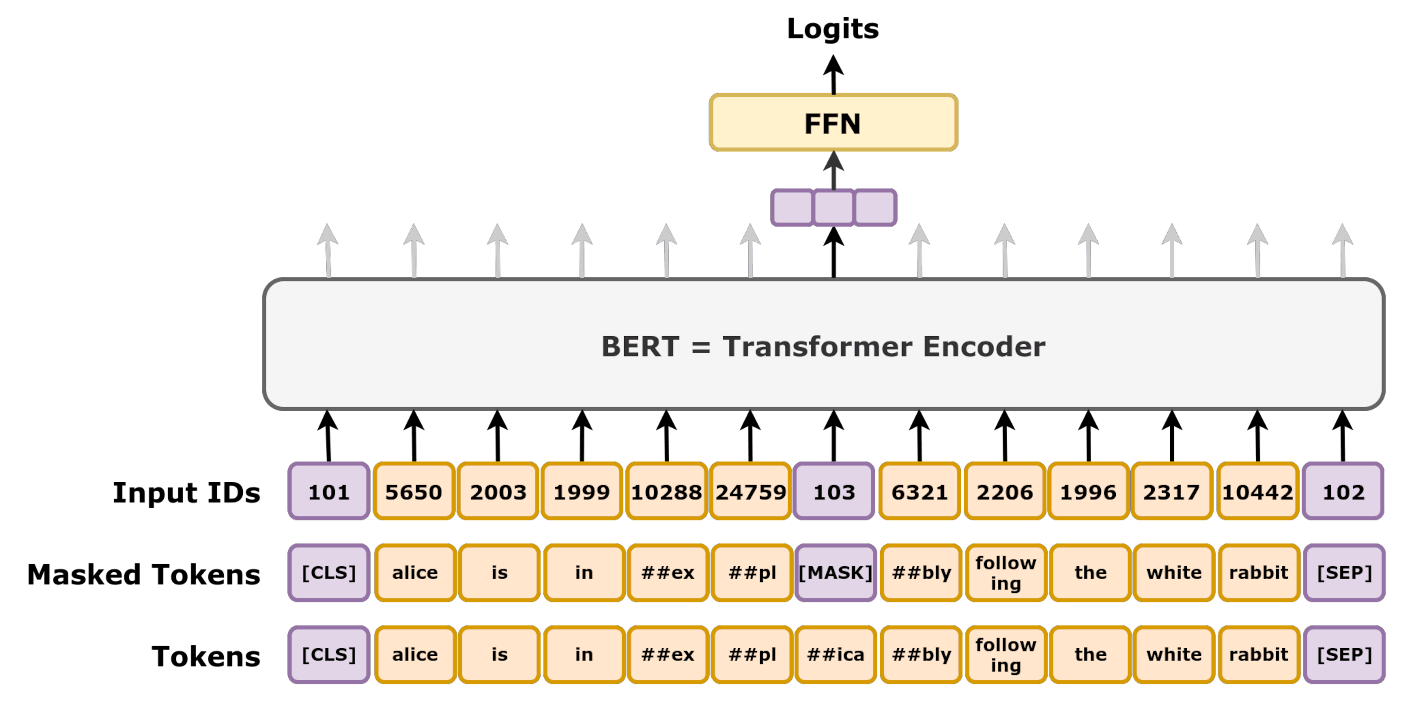
随机掩码来进行预测
下一句预测的任务是给定两个句子,判断这两个句子是否是连续的。主要的过程为:给定两段文本,使模型预测这两段文本在训练语料中是否是顺序出现的,并输出结果为 [IsNext] 或 [NotNext]。第一段文本以特殊标记 [CLS](代表 classify)开头,两个段落之间通过特殊标记 [SEP](代表 separate)分隔。处理完这两段文本后,第一个输出向量(即编码 [CLS] 的向量)会传入一个单独的神经网络,以进行二分类判断 [IsNext] 或 [NotNext]。
例如,给定输入 [CLS] my dog is cute [SEP] he likes playing,模型应该输出 [IsNext]。 而给定输入 [CLS] my dog is cute [SEP] how do magnets work,模型应该输出 [NotNext]。
在预训练后,BERT可以通过较少的资源和较小的数据集进行微调,以优化其在特定任务上的性能,这就是微调阶段。在微调阶段,BERT 通过有监督学习的方式来完成特定的自然语言处理任务。