机器学习简述
写在最前
机器学习是基于多学科交叉融合的新兴学科,而这当中的基石就是数学。因此,如果希望更好地理解机器学习的来龙去脉,而非只是死记硬背各种算法,那么就必须涉及到的数学知识有基本的了解。
简单来说,机器学习的数学基础主要包括线性代数、概率论、统计学以及优化理论等。读者应当具有大学本科理工科专业所具备的数学知识。此外,笔者在学习的过程中发现,在这一基础上还需要了解一些特定方向的数学知识。而对于这一部分知识,可以在数学基础补充这一文章中找到简单的概述。
如今,机器学习的最新研究成果不少已经落地,而一些经典的技术也在各大领域大放异彩。例如,对于计算机相关学科的学习,
机器学习是什么?
学习是一个蕴含特定目的的知识获取过程。其内部表现为新知识的不断建立和修正,外部表现为性能改善。同时,学习既需要外部的材料,也需要内部的推理与记忆的过程。
(广义的机器学习)任何通过数据训练的学习算法都属于机器学习。
机器学习整体上分为三个层面:数据层面、模型层面和学习层面。
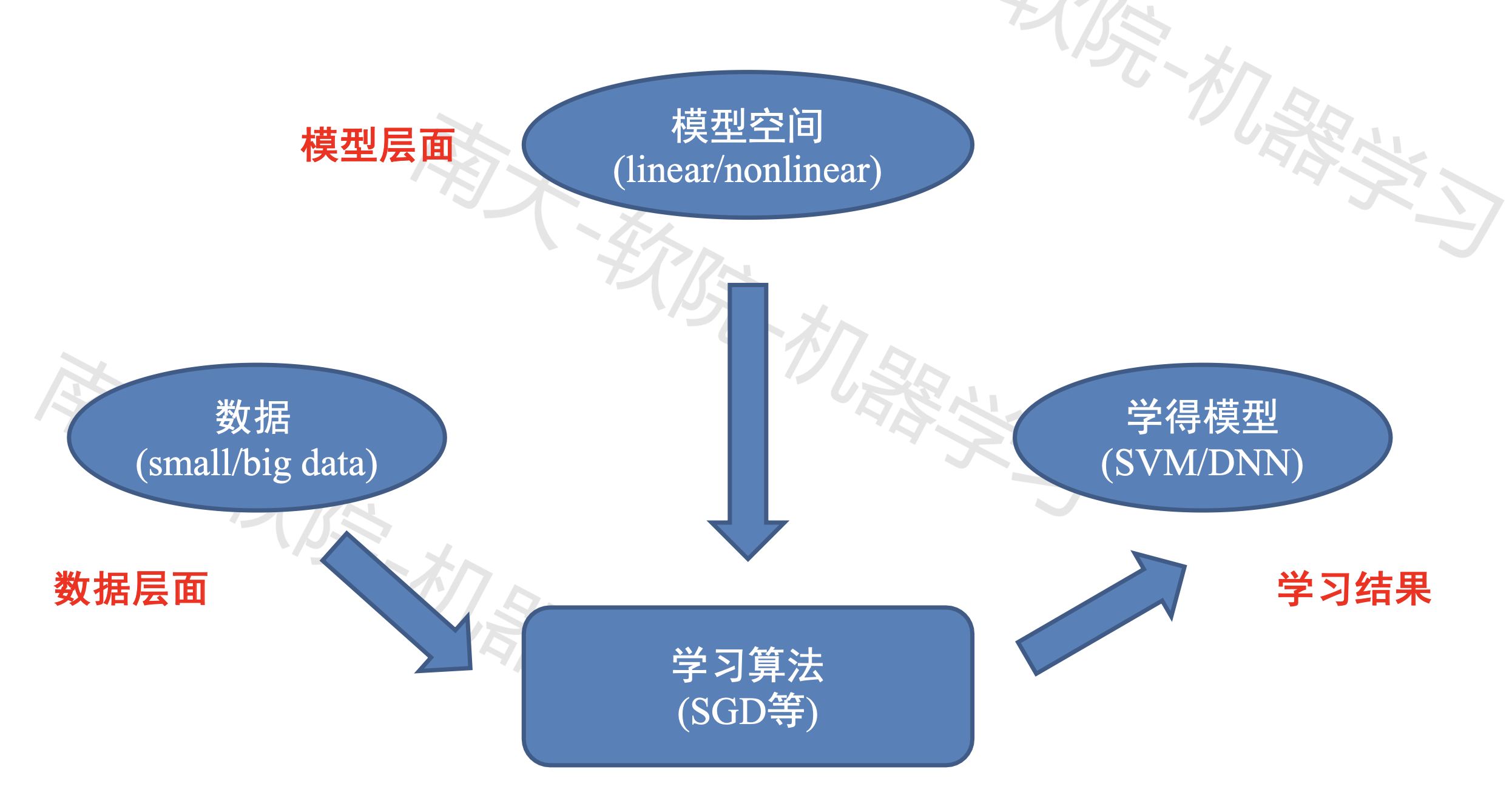
数据层面
数据的类型和特点主要有以下几点,在选择机器学习模型上要首先对数据进行考量:
- 静态和动态
- 小数据和大数据
- 同质和异质:数据类型上的异质性,如结构化数据和非结构化数据;
- 单态和多态
- 小类数和大类数:如二分类(性别)、多分类(个体)等;
- 带噪和缺失数据:如标签带有噪音等;
- 高维数据和非数值数据:如字符串、图像等;
机器学习的成效对于数据与选择的学习方式和模型有强敏感性。在所有时候,都要对具体数据的类型和特点进行分析,而不能硬搬硬套算法,这是机器学习的基本原则。
模型层面
- 任务:分类、回归、聚类、降维、关联规则挖掘等
- 形式上:线性模型/非线性模型
- 体系:浅层、深度、递归等
学习层面
指具体的学习方法(或称算法),例如下面的:
- 经典学习方法:如归纳学习、类比学习、解释学习、决策树、贝叶斯分类器、聚类等;
- 现代学习方法:监督学习/无监督学习、集成学习、强化学习等;
- 混合学习方法
学习方法的关系:深度学习
机器学习的理论基础
最重要的理论模型:
而经典机器学习一般以感知(获取数据)、预处理、特征抽取、特征选择和推理预测为主要内容。现代的机器学习的流程则更加复杂多变,如深度学习、强化学习等。
基本术语
- 数据集:训练集、测试集(可能还有验证集)。
- 示例、样例、样本:关于一个事件或对象的描述。即属性空间表的一行。
- 属性、特征:关于事件或对象在某方面的表现或性质。即属性空间表的一列。
- 属性空间、样本空间、输入空间:由各属性张成的空间。
- 标记:关于示例结果的信息。所有标记的集合称为标记空间或输出空间。
- 特征向量:一个示例在属性空间中对应的坐标向量。
- 模型:学习算法在给定数据和参数空间上的实例化。
- 假设(学得模型对应的某种规律)、真相(实际中的规律)、学习器(即模型)。
- 分类、二分类和回归:分类输出是离散值,二分类的输出是两个类别(正类和反类),回归的输出是连续值。
- 监督学习/无监督学习:由训练资料中学到或建立一个模式,然后依此模式推测新的实例。监督学习是指学习过程中有监督信号(标记),无监督学习则没有。
- 聚类:将训练集中的示例根据一种潜在的概念分为若干组。一般来说,聚类中的数据集不带有标记,而是在学习过程中自行推断类别。
- 泛化能力:学得模型适用于新样本的能力。
一个实际的例子
我们希望根据房屋的面积(平方英尺)和房龄(年)来估算房屋价格(美元)。 为了开发一个能预测房价的模型,我们需要收集一个真实的数据集。 这个数据集包括了房屋的销售价格、面积和房龄。 在机器学习的术语中,该数据集称为训练数据集(training data set) 或训练集(training set)。 每行数据(比如一次房屋交易相对应的数据)称为样本(sample), 也可以称为数据点(data point)或数据样本(data instance)。 我们把试图预测的目标(比如预测房屋价格)称为标签(label)或目标(target)。 预测所依据的自变量(面积和房龄)称为特征(feature)或协变量(covariate)。
归纳偏好
机器学习算法在学习过程中对某种类型假设的偏好。偏好是必然存在的。在实际模型选择和训练中,即要考虑算法的归纳偏好,还要防止过拟合。
一般原则:奥卡姆剃刀。这是一个科学的原则,也是一种哲学思想。它的主要内容即在所有可能的解释中,最简单的解释最有可能是正确的。我们倾向于认为,这一世界的本质是简单的。在机器学习中,我们也倾向于认为,简单的模型比复杂的模型更有效。
另一个理论模型:
统计学基本概念
- 简单统计概念:众数、中位数、平均数、方差、极差、协方差、协方差矩阵等。
- 距离度量函数。
- 函数凸凹性质、凸优化(可以看《凸优化》这本书入门)
- 概率统计:高斯分布、似然、贝叶斯定理等。
从概率框架的角度对机器学习方法分类
- 生成式模型:估计
和 ,然后通过贝叶斯公式计算 。 - 判别式模型:直接估计
。不假设概率模型,直接求一个把各类分开的边界。
新型机器学习发展趋势
- 模型层面:大模型+领域知识,大模型+多模态信息/结构信息,小模型+模型蒸馏+量化
- 优化层面:在线/增量学习、分布式学习+异步优化、加速现有算法
- 数据层面:大数据(带噪声数据学习、多模态数据学习)、小数据(数据提炼蒸馏)
一些机器学习的例子
文本+图像的多模态大模型,通过文本来索引图像 通过文本来输出图像 根据氨基酸序列进行蛋白质结构预测 竞赛程序代码生成 更自然的人机交互 较强的物体一致性、连续性,初步理解世界知识