高可用和高并发
大型网站架构演化历程
在网站的初期阶段,主要是采取简单的单一应用服务器。这一服务器既是应用服务器,也是数据库服务器。这种架构实现简单,但是存在单点故障的问题,且性能也较低。
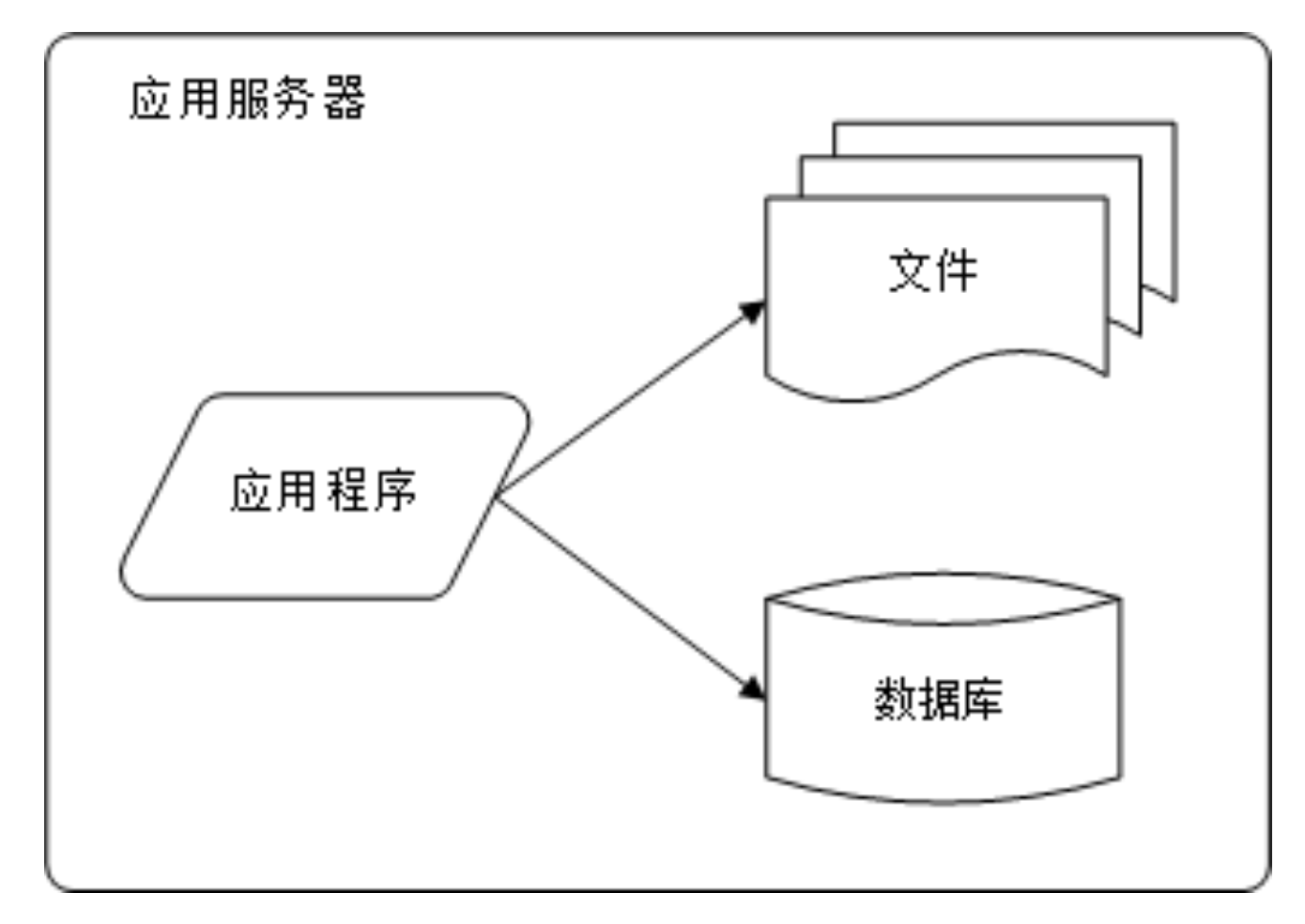
初始阶段的网络架构
之后,本着职责分离的原则,将应用服务器和数据库服务器分开,形成两层架构。这种架构解决了单点故障的问题,但是应用服务器的性能仍然是瓶颈。在此基础上,又引入了分布式缓存服务器来改善网站性能。缓存的主要思想是将数据库中的数据储存到缓存服务器中,以减轻数据库的压力。
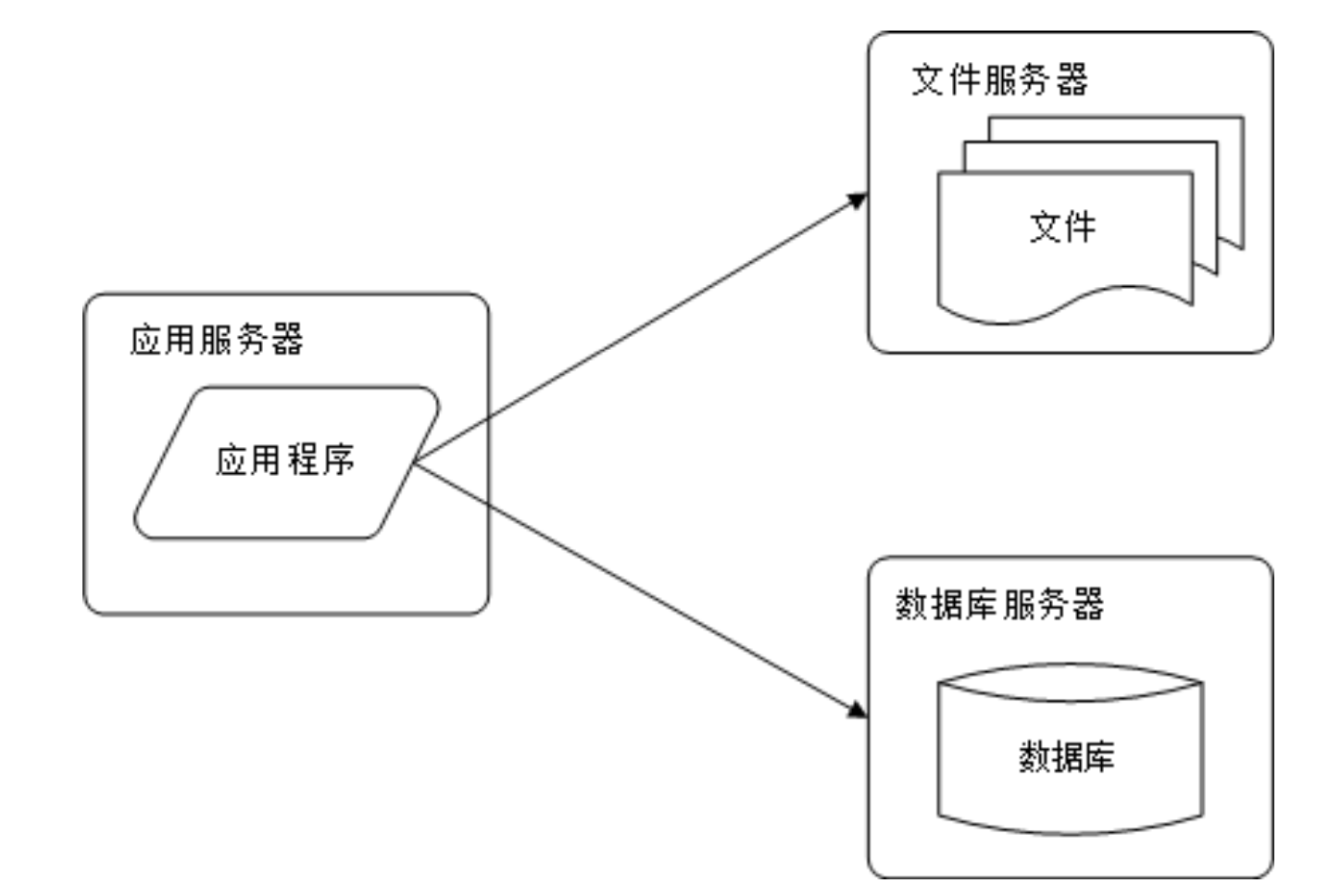
应用服务和数据服务分离
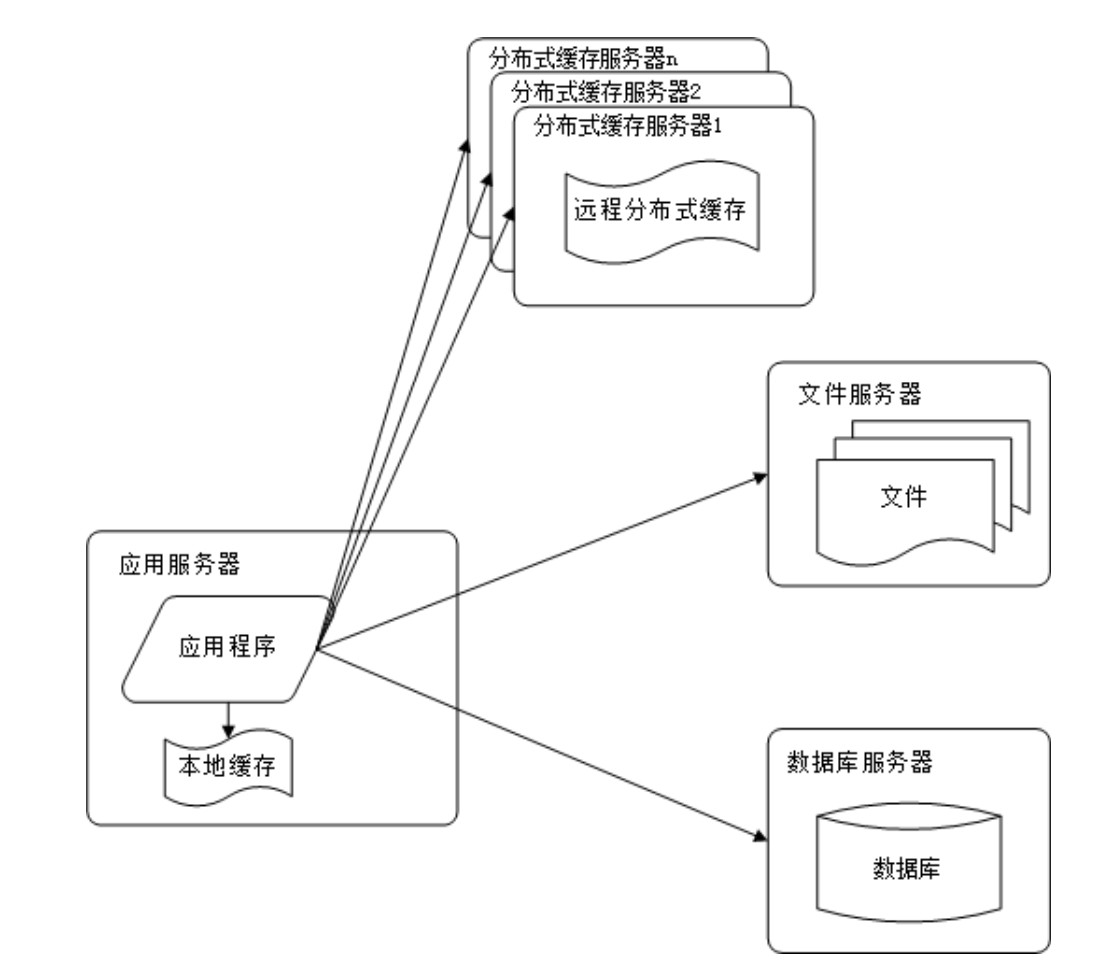
使用缓存改善网站性能
但是,随着网站的用户量不断增加,两层架构的性能也逐渐达到瓶颈。为了解决这一问题,引入了服务器集群和负载均衡调度服务器来改善网站的并发处理能力。服务器集群指的是多台服务器组成一个集群,负载均衡调度服务器则是将用户的请求分发到不同的服务器上,以实现负载均衡。
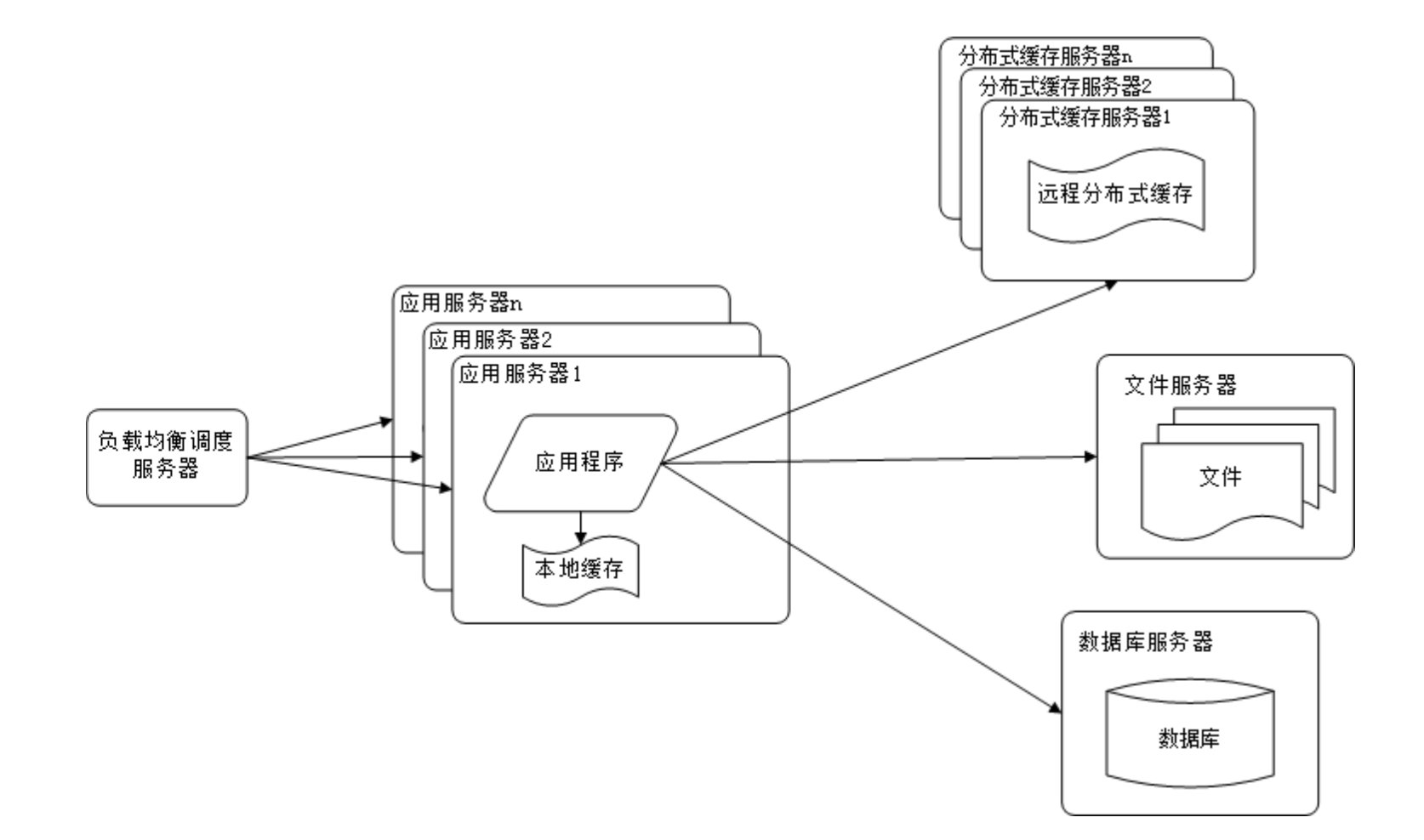
使用应用服务器集群改善网站的并发处理能力
此外,还有不同的其他技术来进一步提高网站的性能,如数据库读写分离、反向代理、CDN、分布式文件系统、业务拆分和分布式服务等。
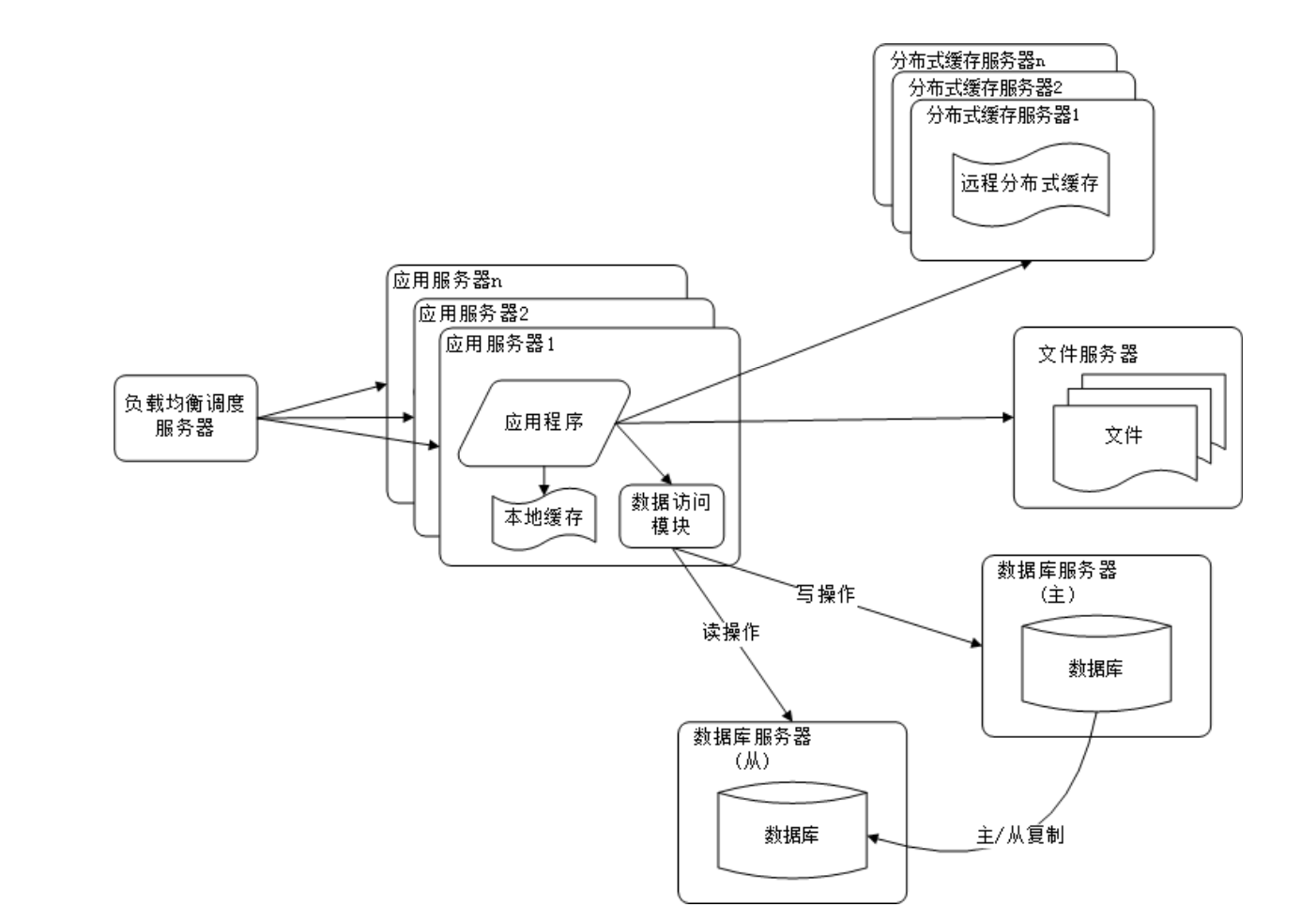
数据库读写分离
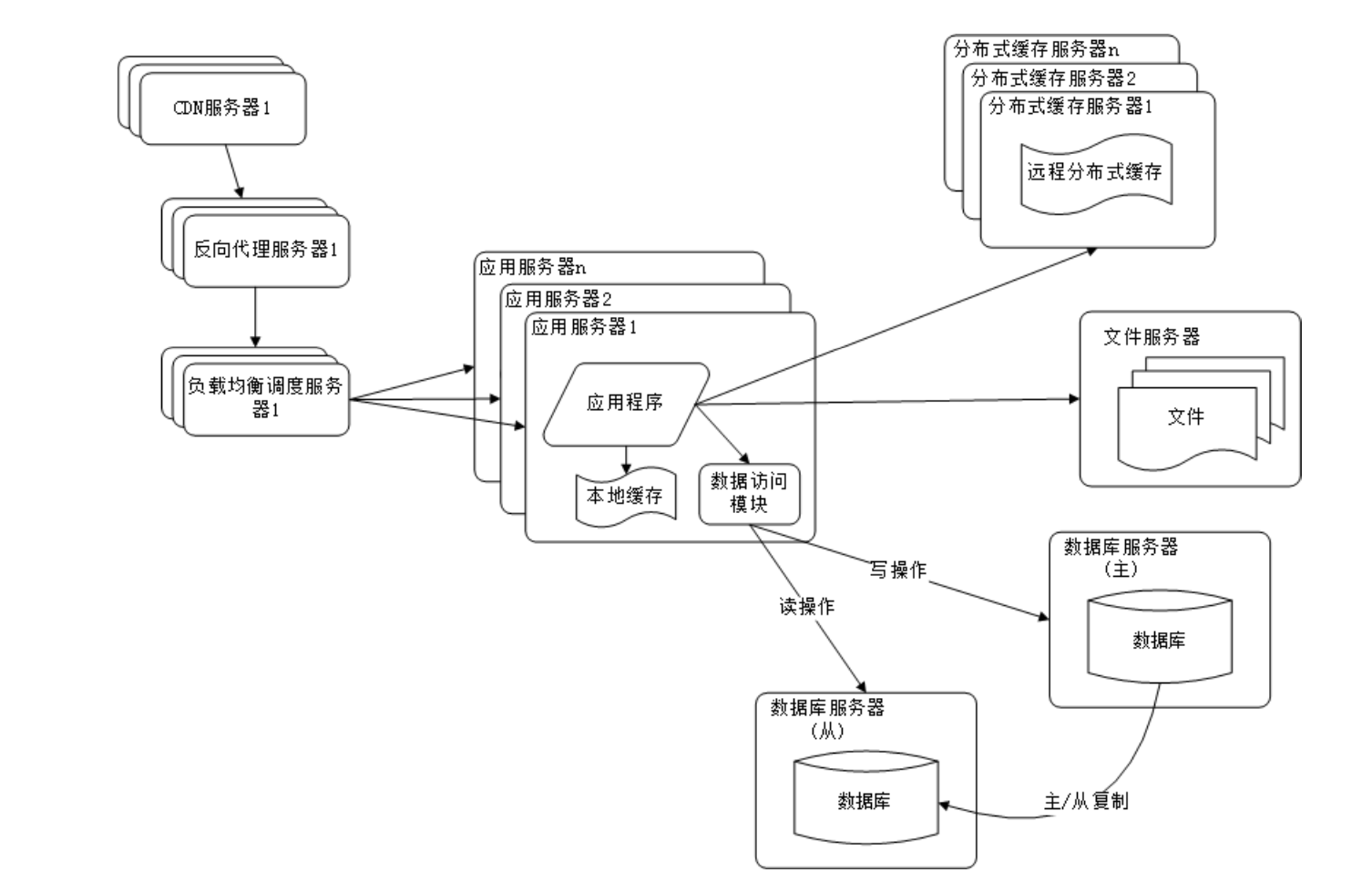
使用反向代理和 CDN 加速网站响应
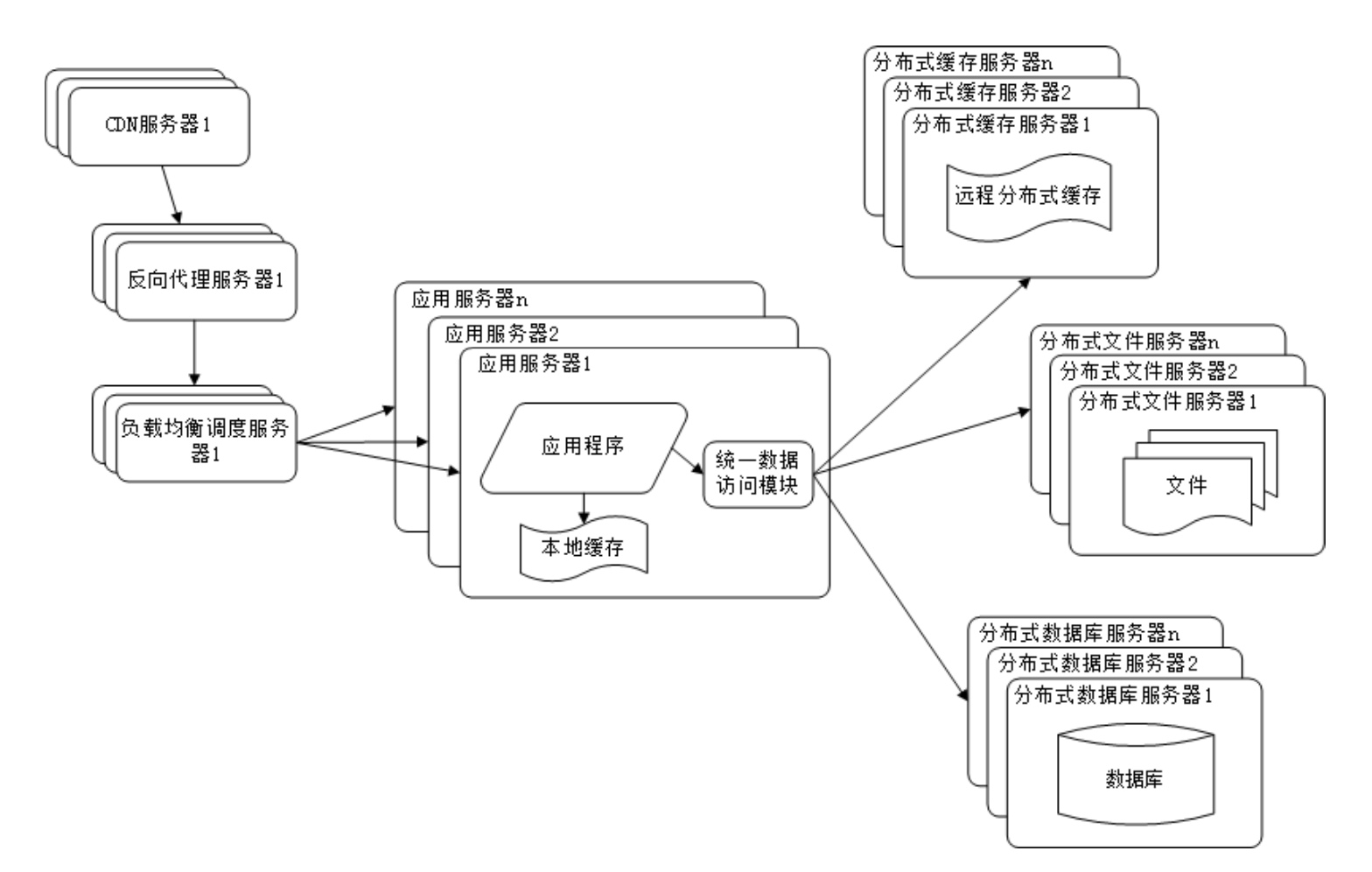
使用分布式文件系统和分布式数据库系统
高可用
高可用性是指系统能够在长时间内正常运行,不间断地提供服务。
负载均衡
将用户的请求映射到多台服务器上。可以在第四层(传输层)和第七层(应用层)进行负载均衡。具体的算法有 Round Robin(循环)、Weighted Round Robin、IP Hash(同 IP 同服务器) 等。
反向代理
反向代理服务器是指代理服务器接收客户端的请求,然后将请求转发给内部服务器。反向代理服务器主要的功能有:
proxy cache:可以提供缓存来减少服务器的压力;gzip:通过压缩响应数据,可以减少传输数据的大小。Nginx 会在数据发送到客户端之前进行压缩,但是对于已经压缩过的数据不会进行二次压缩(比如代理服务器压缩过一次了)。location:用于匹配 URI,并指定如何处理该 URI。通过 location 配置,Nginx 能够根据请求路径将请求转发到特定的上游服务器、文件系统或应用程序服务。
location 配置
在 Nginx 反向代理配置中,location 指令用于匹配 URI,并指定如何处理该 URI。通过 location 配置,Nginx 能够根据请求路径将请求转发到特定的上游服务器、文件系统或应用程序服务。
基本语法
location 指令的基本语法如下:
location [modifier] <URI> {
# 配置内容
}- modifier:匹配模式,用于指定匹配方式。
- URI:请求的 URI 前缀,用于决定哪种类型的 URI 可以匹配该
location块。
匹配模式(Modifiers)
location 指令的 modifier 是可选项,用于控制 URI 匹配的类型。主要有以下几种匹配模式:
精确匹配
=:只匹配与给定 URI 完全一致的请求,优先级最高。nginxlocation = /exact/path { # 仅匹配 URI 为 /exact/path 的请求 }前缀匹配(无
modifier):匹配以指定前缀开头的 URI,当多个前缀匹配同时存在时,Nginx 会选择最长的匹配。nginxlocation /prefix { # 匹配所有以 /prefix 开头的 URI }正则匹配
~和~*:~:区分大小写的正则表达式匹配。~*:不区分大小写的正则表达式匹配。
nginxlocation ~ ^/images/.*\.(jpg|png)$ { # 匹配 /images/ 开头,且文件后缀为 .jpg 或 .png 的 URI } location ~* ^/videos/.*\.(mp4|avi)$ { # 不区分大小写匹配 /videos/ 开头,后缀为 .mp4 或 .avi 的 URI }通配符匹配
^~:仅用于前缀匹配,不对 URI 进行正则解析,并且优先级高于正则表达式。nginxlocation ^~ /static/ { # 优先匹配 /static/,且不再尝试匹配正则 }
匹配顺序
在 Nginx 中,location 指令的匹配顺序如下,一旦找到匹配的 location 块,Nginx 将停止进一步的匹配:
=精确匹配;^~通配符匹配;- 正则表达式
~和~*匹配(按配置顺序匹配,第一个匹配成功的生效); - 前缀匹配(无 modifier)(最长前缀匹配)。
隔离
在前面的架构设计中,我们多次强调了隔离的重要性,包括业务级的隔离、服务级的隔离、数据级的隔离和物理级隔离等等。对高可用性来说,隔离也是非常重要的。隔离的目的是减少单点故障的影响范围,提高系统的可用性。主要的隔离层次有:
- 线程隔离:核心业务线程池、非核心业务线程池。
- 进程隔离:不同的子系统之间使用不同的进程。
- 集群隔离:如为秒杀服务等有特殊要求的服务提供单独的商品服务集群。
- 机房隔离:每个机房的服务都有自己的服务分组。
限流
限流即限制系统的访问速率,以保护系统不被过多的请求拖垮。主要的限流算法为令牌桶算法,它的思想是创建一个固定令牌容量的桶,并按照固定速率往桶里添加令牌。根据请求的数量来取出令牌进行使用。
一般来说,限流的对象包括总(或某个接口)的并发/连接/请求数、总(或某个接口)的资源数等。
降级
降级指的是在系统出现故障时,为了保证核心功能的正常运行,暂时关闭一些不重要的功能。降级的选择原则是优先保证核心功能的正常运行,衡量标准有按功能、按是否自动化、按日志级别和按系统层次等。
降级发生的原因有很多种,如超时降级、统计失败次数降级(自动化监控)、故障降级和限流降级等。
回滚
回滚分为事务性的回滚和非事务性的回滚。事务性的回滚是指在事务执行过程中出现错误,需要回滚到事务开始前的状态,一般来说是良性的。非事务性的回滚包括代码库回滚、部署版本回滚、数据版本等,主要是由于代码中出现了问题或系统中出现了不可预知的错误,一般是恶性的。
压测和预案
压力测试是指对系统进行压力测试,以验证系统的性能和稳定性。线下的压测可以在客户端模拟大量的请求,线上可以更进一步,仔细测试系统各个功能的抗压能力。线下压测的工具有 JMeter等,线上压测方法有读压测、写压测、混合压测、仿真压测、引流压测、隔离集群压测、显示集群压测、全链路压测等。
此外,还需要制定相应的应急预案提高容灾能力。
高并发
高并发是指系统能够同时处理大量的请求。为了实现高并发,在实践中经常考虑以下几个方面。
应用级缓存
应用级缓存是指将数据缓存在应用服务器中,以减轻数据库的压力。常见的应用级缓存有 Redis、Memcached 等。应用缓存很大程度提高了系统的性能。
缓存这一部分与计算机中的 Cache 有很大的相似性,许多概念,包括缓存命中率、替换算法等都是相通的。缓存还有两种使用模式 Cache Aside 和 Cache as SoR,前者指业务代码主动维护缓存,后者指缓存作为数据源,真实的数据源不可见,只能通过缓存来访问。
此外,还可以通过分布式缓存(如 Redis 集群)解决热点数据问题。
连接池
数据库连接池(Connection pooling)是在程序启动时创建一定数量的数据库连接,并将这些连接保存在一个连接池中。当需要连接数据库时,从连接池中取出一个连接,使用完毕后再将连接放回连接池中。这样可以减少数据库连接的创建和销毁次数,提高数据库的访问速度。
异步处理
某些服务应当设置为异步处理,以提高系统的并发处理能力。异步处理经常和队列结合使用,实现数据同步、流量削峰等功能。队列的生产者是用户请求,消费者是后台服务。
常用的消息队列有 RabbitMQ、Kafka 等。
扩容
- 水平扩容:通过增加服务器的数量来提高系统的并发处理能力。
- 垂直扩容:通过增加服务器的硬件配置来提高系统的并发处理能力。
- 分库分表:通过将数据库分为多个库和表(取模、按时间分区),来提高数据库的并发处理能力。