线性模型
线性可分性
令
感知机
感知机由美国学者
即找到一个超平面线性方程
因此,当
线性模型
试图去学得一个通过属性的线性组合来进行分类的分类函数,其向量形式为
线性回归
线性回归的求解目标是优化参数,使得预测值接近真实值。即优化
求导的一个技巧是把所有的样本放在一个矩阵中,矩阵中的每一行都是一个样本,并在矩阵后面加上一列全为
这样,线性回归的目标就变成了优化
对损失函数求导,得到
令导数为
如果我们令
再者,我们继续推广,令某单调可微的连续函数
二分类任务
线性回归模型产生的实值输出的范围可能是
- Sigmoid 函数:
,其中 ; - 单位阶跃函数:
;
其中,
对数几率回归(对率回归)
对数几率回归是一种广义线性回归,它的联系函数正是
根据对数的性质,我们可以得到:
将
对数几率回归的损失函数是似然函数的负对数(加一个负号转化为最小化问题),对于数据集
其中,
接下来,我们进一步化简可以得到:
推导过程
显然,对于似然项,我们可以写成综合两种预测情况的形式:
那么,代入原式,我们可以得到:
最后一步的推导用到了对数几率的定义,即
在最后一步代入即可。
线性判别分析
线性判别分析
例如,给定数据集
- 同类样例的投影点尽可能接近,即
尽可能小; - 异类样例的投影点尽可能远离,即
尽可能大。
推导过程
我们来证明在
对于投影后的每一个样本
对于协方差,可以参考这篇文章。
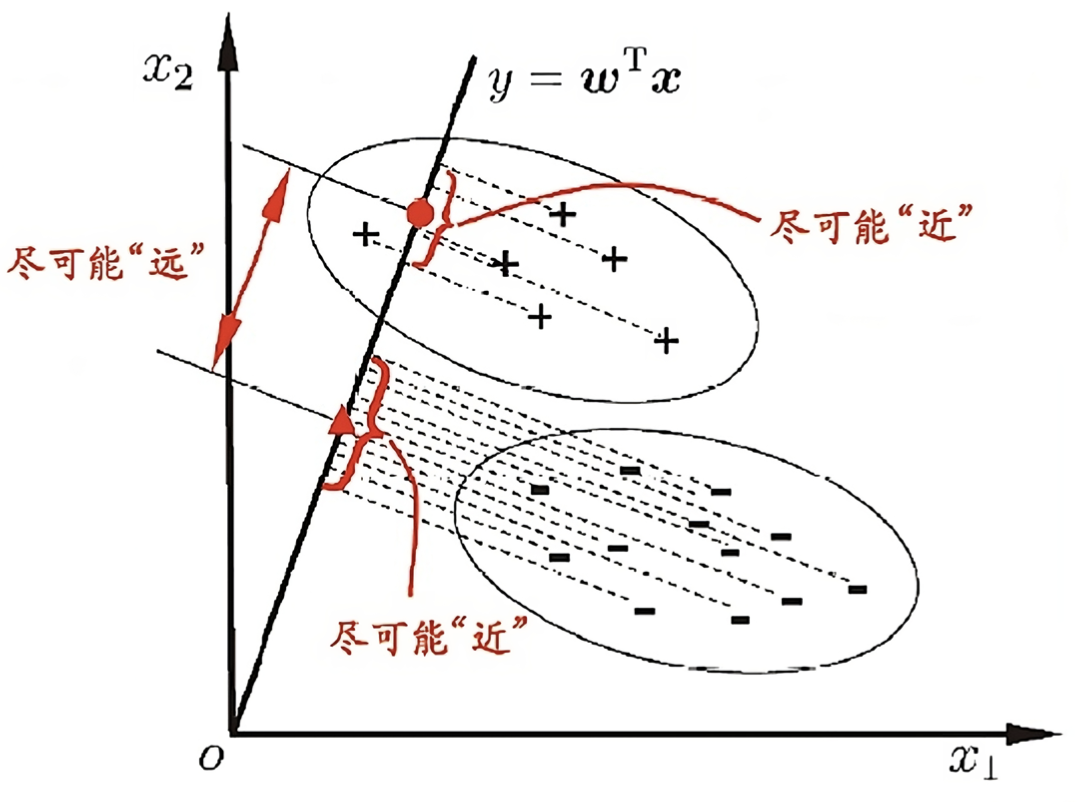
同类接近 异类远离
因此,我们可以定义广义瑞利商:
其中,
对于
推导过程
由于
下面我们使用拉格朗日乘子法,定义拉格朗日函数:
对
令导数为
倒数第二步,我们定义
多分类任务
对于多分类任务,我们可以使用一对多的策略,即将多分类任务转化为多个二分类任务。主要分为两种策略,一种是一对多,另一种是一对一。
- 一对多:对于
个类别,我们训练 个分类器,第 个分类器将第 类作为正类,其他类作为负类。在测试时,我们选择分类器输出最高的类别作为预测结果。 - 一对一:对于
个类别,我们训练 个分类器,每个分类器只区分两个类别。在测试时,我们选择分类器输出最多的类别作为预测结果。
这两种策略的问题在于类别不平衡,即某些类别的样本数远远大于其他类别的样本数。因此,我们可以使用加权损失函数,即对于每个类别,我们可以设置一个权重,使得每个类别的损失函数对最终的损失函数的贡献相同。(当然,估计类别的权重也比较困难)