数学基础补充
在机器学习领域中,数学是非常重要的基石,涉及到了代数学、微积分、概率论、统计学等多个分支。相对于传统的系统化的数学学习,机器学习中的数学学习更加注重于应用,因此也就更加分散和颗粒化。可是,从个人的切身体会来看,对于非数学专业的学生或相关人员来讲,如果没有系统地学习过这些数学分支,这些知识可能看起来并没有那么“基础”。这样看来,我们可以以机器学习的视角出发,快速地填补一些知识漏洞,或者去重温这些数学知识。这篇文章的目标就是集中地整理机器学习中所涉及的数学基础知识。全文以知识点的方式布局,并且假定读者已经具备了大学本科层次的高等数学和线性代数的基础知识(即绝大多数理工科专业数学基础课程的知识)。
矩阵的导数
这一部分不需太纠结,能理解公式的意义即可。
在高等数学中,我们学过一元函数
我们在线性代数中还学过向量和矩阵。在实际应用中我们发现,很多运算都可以简记为向量和矩阵的形式,并且它们还有一些良好的性质来方便我们计算。那么,导数的概念是否可以继续推广呢?先来看一个简单的例子。
符号说明
- 用大写粗体字母表示矩阵,如
;用斜体字母和脚标表示矩阵中的元素,如 或 ; - 用小写粗体字母表示向量,如
;用小写斜体字母和脚标表示向量中的元素,如 ;如没有特殊说明,约定向量为列向量; - 用小写斜体字母表示标量,如
或 。
对于随机变量:
- 单一的随机变量用大写斜体字母表示,如
;对于随机变量的取值,我们用小写斜体字母表示,如 ; - 随机变量组成的向量,我们用大写粗体字母加向量上标表示,如
;用大写斜体字母和脚标表示向量中的元素,如 ; - 随机变量组成的矩阵,我们直接用大写粗体字母表示,如
;用大写斜体字母和脚标表示矩阵中的元素,如 。
梯度 梯度是一个向量,表示某一多元函数在该点处的方向导数沿着该方向取得最大值。对于一个具有一阶连续偏导数的多元函数
这里,
这样,我们就可以把梯度的公式简写为
由此我们可以看出,向量和矩阵的求导其实就是对多元函数求偏导,只不过是将自变量、因变量和结果排列成了向量或矩阵的形式,是一种简记的方式。当然,在我们全部定义后,它还可以推出很多方便的性质可用于推导和计算。这就是矩阵微分的一大内容。因此,下面我们列出完整的定义。
| 自变量 / 因变量 | 矩阵 | 向量 | 标量 |
|---|---|---|---|
| 矩阵 | 不讨论 | 不讨论 | |
| 向量 | 不讨论 | ||
| 标量 | 平凡 |
So...列向量还是行向量?
在计算向量或矩阵的导数时,一个问题就是自变量、因变量和结果到底应该怎么排列呢?比如,分母应该是行向量还是列向量?结果呢?前文说过,这只是一个排列方式,似乎一个小小的转置并不重要。但我们最好还是仔细定义来澄清这一点。
一般而言,分为两种模式,即分子布局和分母布局。它们的选择是随意的,但在一次求导运算中,只能选择一种布局,不能杂糅。
上文的表格中,我们使用的就是分母布局。它的含义是,结果的维数必须要与分母的维数或分子的转置的维数相同。进一步说明:第一,我们只需要一个分子或分母的一个判据即可:也就是说,如果分母为标量,那只能看分子的转置,反之亦然。第二,当选择的判据是向量而结果是矩阵时,若是行向量就只用看矩阵的列数是否等于向量的维数,若是列向量就只看行数。
分子布局与分母布局刚刚相反,两者的差异在于一个转置。
但在实际应用中,我们往往会选择混合布局,即在一次求导运算中,我们可以选择不同的布局。这样做的好处是,可以减少转置的次数,提高计算效率。但是,这样可能会增加一些混乱,需要我们时刻注意自己选择的布局。
有了上面的说明,就可以利用微分学的知识和一点点代数的能力,推导出很多简明的结论。下面我们给出一些。
标量对向量
,其中 是一个常向量(这里“常”的意思是指不是关于 的函数,下同); ; ,这是因为
- 若
都是关于 在对应点可导的标量函数,则 ; ; ; ;
这些结论通过学过的微分学知识和矩阵的性质可以推导出来。至于向量对标量的导数,相对而言就更加简单,这里就不再赘述。
向量对向量
先给出一些简单的结论:
,其中 是一个常向量; ,其中 是一个常标量, 是单位矩阵; ,其中 是两个向量; ,其中 是一个向量函数(输入向量、输出向量), 是一个向量;
接下来是一些稍微复杂一点的结论:
,其中 是一个标量, 是一个向量;(使用时一定要注意布局) ,其中 是一个常矩阵, 是一个向量;
其他常用结论
,其中 是两个常矩阵;由此,将 代替 可以推出
协方差
在概率统计中,协方差用来衡量两个变量的相关程度。对于两个随机变量
其中,
定理
定理
定理
定理
对于两列随机变量
可以看出,协方差矩阵是一个对称矩阵。对角线上的元素就是各个随机变量的方差。
例如,给定一个含有
条件概率与贝叶斯公式
对于在
先验概率指在考虑某些已然确定的事实(观测数据)前估计的概率分布,而后验概率指将那些将观测数据纳入考虑范围时的概率。先验概率描述了随机变量本身的随机程度,而后验概率为基于试验和调查后得到的概率分布。
例如,
其中,
概率是已知参数的情况下观测到某一事件的可能性,而似然是在已知某一事件的情况下推测到某一参数的可能性。例如,对于一枚硬币上抛十次,如果假定硬币是均匀的(参数),那么我们可以求得到五次正面的概率;而如果我们已知抛十次硬币得到了五次正面,那么我们可以求得硬币是均匀的可能性,这就是似然。
已知有
需要注意的是,似然函数并不需要满足归一性,即
例如,对于抛硬币的例子,已知事件
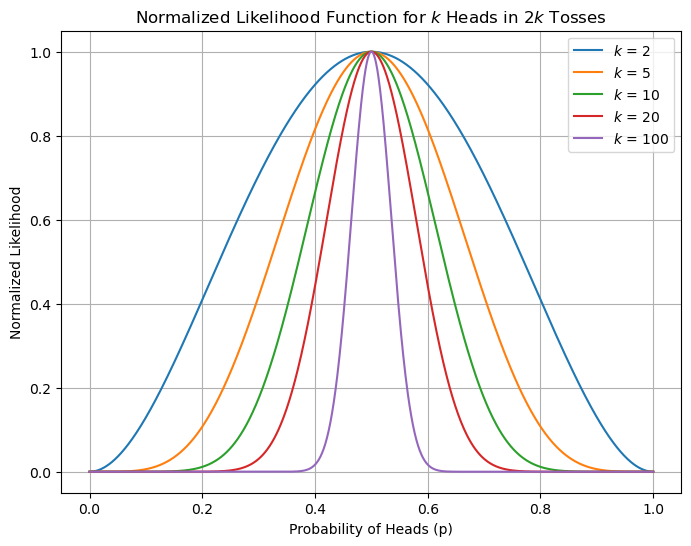
那么,我们可以通过似然函数来估计硬币的正面概率。下图绘制了这一似然函数的图像(
实现代码
# Try to run this code on your local machine!
import numpy as np
import matplotlib.pyplot as plt
p_values = np.linspace(0, 1, 1000)
def likelihood(p, k):
return p**k * (1 - p)**k
k_values = [2,5,10,20,100]
plt.figure(figsize=(8, 6))
for k_value in k_values:
likelihood_value = likelihood(p_values, k_value)
normalized_likelihood_value = likelihood_value / np.max(likelihood_value)
plt.plot(p_values, normalized_likelihood_value, label='$k$ = '+str(k_value))
plt.title('Normalized Likelihood Function for $k$ Heads in $2k$ Tosses')
plt.xlabel('Probability of Heads (p)')
plt.ylabel('Normalized Likelihood')
plt.grid(True)
plt.legend()
plt.show()由上图我们也可以看出,随着上抛的次数增多,似然函数的峰值会越来越尖锐,这是因为随着抛硬币的次数增多,我们对硬币正面概率的估计会越来越准确。显然,当我们抛两次硬币得到一次正面时,和抛两百次硬币得到一百次正面时,我们对硬币均匀度的把握会有显著不同。这就是极大似然估计的核心思想。
在机器学习领域,通常我们会使用下面的记号:
是类别 的先验概率; 是特征 的先验概率; 是类别 的似然函数; 是类别 的后验概率;
距离度量函数
对于两个样本向量
- 欧式距离
- 余弦相似性(类似角度)
- 曼哈顿距离
- 切比雪夫距离
- 马氏距离
范数
范数是一个函数,它将向量映射到非负值。对于一个向量
上文的曼哈顿距离、欧式距离和切比雪夫距离分别是
马氏距离的计算
马氏距离的
例如,对于三个样本向量
- 计算协方差矩阵
: - 确定各维度向量
, ; - 计算协方差矩阵
;
- 确定各维度向量
- 计算协方差矩阵的逆
; - 计算马氏距离
。
马氏距离的优点是,相对欧式距离更加准确,因为它考虑了各维度之间的相关性并进行了归一化。
高斯分布
高斯分布是一种连续概率分布,也称为正态分布。正态分布是在统计中以及众多统计测试中最广泛应用的一类分布。它的概率密度函数为:
其中,
对于
其中,